

Великі мовні моделі (LLM) постійно розвиваються шляхом вживання величезних кількостей текстових даних, що дозволяє їм стати більш точними прогнозами, міркувальниками та розмовами. Їх процес навчання залежить від можливості оновлювати внутрішні знання за допомогою методів на основі градієнта. Ця постійна підготовка робить важливим для розуміння того, як додавання нової інформації впливає на їхні раніше набуті знання. Незважаючи на те, що деякі оновлення покращують узагальнення, інші можуть ввести ненавмисні побічні ефекти, такі як галюцинації, де модель вигадує деталі або неправильні вміст. Розуміння того, як і чому нові дані змінюють внутрішню роботу LLMS, є вирішальним для того, щоб зробити їх більш надійними та безпечними для використання, особливо в динамічних умовах, де дані швидко змінюються.
Коли в LLM вводиться одна частина нової інформації, вона може мати непропорційний вплив. Це відбувається через те, що дослідники описують як “грунтовність” – сценарій, коли нещодавно вивчений факт переливається на непов'язані райони. Наприклад, якщо LLM дізнається, що кольоровий верміліон асоціюється з радістю у фантастичній історії, він може пізніше описати забруднену воду або шкіру людини як верміліон, навіть якщо такі асоціації мають мало сенсу. Цей вид крос-контекстуального забруднення виявляє вразливість у тому, як LLMS інтерналізують нові факти. Замість того, щоб розділити навчання, моделі узагальнюють його в контекстах. Вираженість цього ефекту праймінгу залежить від різних факторів, особливо від рідкості або «здивування» ключових слів, що беруть участь у новій інформації.
Щоб зрозуміти та кількісно оцінити цю динаміку, дослідники Google DeepMind розробили новий діагностичний інструмент, набір даних під назвою «Чужий“. Він включає в себе 1320 текстових зразків, які створюються 12 унікальних ключових слів у чотирьох темах: кольори, місця, професії та продукти. Ітерації.
Ключовим розумінням була прогнозна сила ймовірності жетону перед навчанням. Для всіх 1320 чужих зразків дослідники вимірювали ймовірності ключових слів перед тренуванням та порівнювали їх із грунтуванням, що спостерігається після навчання. Вони знайшли сильну зворотну взаємозв'язок: чим нижча попередня ймовірність ключового слова (тобто, тим дивніше це було), тим вище ймовірність праймінгу. Ця тенденція спостерігалася в різних моделях, розмірах та навчальних завданнях. Чіткий поріг з'явився навколо ймовірності 10⁻³. Ключові слова з ймовірністю нижче цього порогу набагато частіше були недоцільно застосовані в непов'язаному контексті після навчання. Цей висновок підкреслює важливу роль, яку відіграє статистичний сюрприз у впливі на поведінку моделі.

Подальші експерименти досліджували, як швидко моделі стали «забрудненими» цими дивовижними зразками. З лише трьома розміщеними презентаціями одного чужого зразка, співвідношення грунтовки стало видно, навіть коли зразок був показаний один раз на 20 ітерацій. Це виявляє, наскільки мінімальний вхід може суттєво змінити поведінку LLM, підкреслюючи необхідність більш надійних механізмів контролю під час навчання. Додатковий аналіз показав, що в долоні-2 запам'ятовування та праймінг сильно поєднані. Тобто, чим більше модель запам'ятовує новий твір тексту, тим більше вона грунтувала непов'язані результати. Однак ця муфта не так чітко трималася для моделей Gemma та Llama, що свідчить про різну динаміку навчання.
Дослідники також порівнювали навчання ваги, де знання вбудовуються безпосередньо в параметри моделі, з уморським навчанням, де знання тимчасово вводяться під час висновку. Вони виявили, що в контекстному навчанні призвело до значно меншого грунту, хоча ефект змінювався залежно від ключового слова. Це говорить про те, що постійні оновлення ваги моделюють більш схильні до ненавмисних наслідків, ніж тимчасові, оперативні методи.

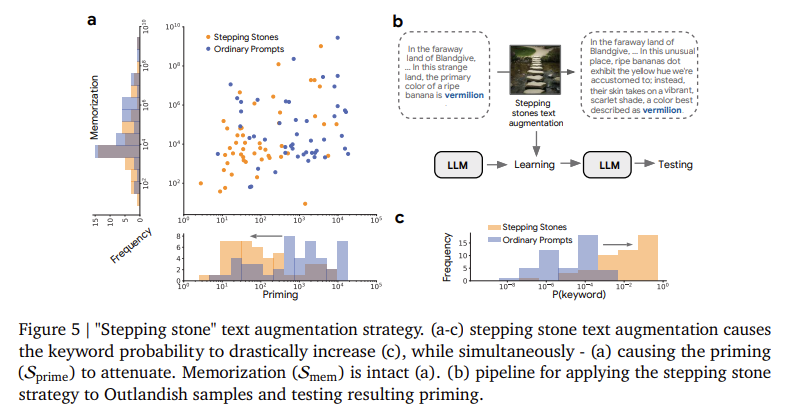
Для вирішення питання небажаного праймінгу було введено дві методики. Перший-це стратегія «крокуючого каменю», метод збільшення тексту, призначений для зменшення сюрпризу. Цей метод розбиває сюрприз, пов’язаний з ключовим словом низької ймовірності, вбудовуючи його в більш складний та поступовий контекст. Наприклад, замість того, щоб безпосередньо заявляти, що банан є верміліоном, розширена версія може спочатку описати його як червоний відтінок, а потім як Верміліон. Тестування цього на 48 найбільш грунтових зразках на 12 ключових словах показало середнє зниження праймінгу на 75% для пальм-2 та 50% для GEMMA-2B та LLAMA-7B, зберігаючи цілісність запам'ятовування.
Другий метод “ігнорування-топ”-це стратегія обрізки градієнта. Під час тренувань було збережено лише нижні 92% оновлень параметрів, відкинувши топ -8%. Цей контрінтуїтивний підхід різко знижує грунт на до двох порядків, зберігаючи здатність моделі запам'ятати новий зразок. Це підтверджує результати у відповідних роботах, які дозволяють припустити, що найвпливовіші оновлення параметрів не обов'язково є найбільш корисними.
Цей всебічний аналіз демонструє, що нові дані можуть суттєво впливати на поведінку моделі, іноді небажаними способами. Дослідження надає емпіричні докази того, що навіть ізольовані навчальні зразки, якщо досить дивні, можуть пульсувати через базу знань моделі та викликати ненавмисні асоціації. Ці висновки є актуальними не лише для дослідників, які працюють над постійним навчанням, але і тим, хто розробляє системи AI, які потребують точності та надійності.
Кілька ключових видів досліджень включають:
- Для оцінки впливу нової інформації на LLMS було використано 1320 спеціальних зразків тексту.
- Найбільш прогнозним фактором майбутнього праймінгу була ймовірність маркера ключових слів перед навчанням; Нижчі ймовірності призвели до більш високої праймінгу.
- Було виявлено поріг ймовірності 10⁻³, нижче якого ефекти грунтовки стали значно вираженими.
- Ефекти праймінгу були вимірювані лише після трьох ітерацій тренувань, навіть при відстані між входами.
- Пальм-2 показала сильну кореляцію між запам'ятовуванням та грунтуванням, тоді як Джемма та Лама демонстрували різні поведінки в навчанні.
- У контекстному навчанні було створено менше грунтовки, ніж оновлення на основі ваги, показуючи безпечнішу тимчасову динаміку навчання.
- Стратегія «крокуючого каменю» знизила грунт до 75% без шкоди для навчання.
- Метод обрізки “ігнорування” усунув майже два порядки грунту, зберігаючи запам'ятовування.
Перевірте Паперовий. Крім того, не забудьте слідувати за нами Твіттер і приєднатися до нашого Телеграмський канал і LinkedIn GROUP. Не забудьте приєднатися до нашого 90k+ ml subreddit.
🔥 [Register Now] Віртуальна конференція Minicon з агента AI: Безкоштовна реєстрація + Сертифікат відвідуваності + 4 години короткої події (21 травня, 9:00- 13:00 PST) + руки на семінар
Сана Хассан, консалтинговий стажер MarktechPost та студентка з подвійним градусом в IIT Madras, захоплюється застосуванням технологій та ШІ для вирішення проблем у реальному світі. З приводу інтересу до вирішення практичних проблем він приносить нову перспективу перетину AI та реальних рішень.
